


The question
When speaking of performance in relation to the Internet, we often focus exclusively on capacity in bits per second (bps). We assume that a capacity of 10 Gb/s (ten gigabits per second) is better than 1 Gb/s. This is true for some applications, but not for all. The important variable is often latency, i.e. the time a message takes to get from one point to another. A millisecond is enough when both machines are in the same geographical region1, but it takes several milliseconds to communicate with other countries in Western Europe, and several tenths of a second to get to the USA2, not to mention the Far East or Africa. So what do a few milliseconds here or there matter, you may well ask. The problem is that some transactions need to wait for a response, and several messages to and fro may be required. So it’s important to optimise performance by limiting this to-and-froing during which the machines spend more time waiting than they do working.
A good example is that of the TCP (Transmission Control Protocol), the transport protocol currently most used on the Internet. Most application protocols, including the famous HTTP (Hypertext Transfer Protocol) use TCP3. TCP relies on the principle of connections having first been established between machines. First of all, IP (Internet Protocol) packets are exchanged, so as to be relatively sure that the two machines consent to talk to each other. And it is only then that actual data are exchanged. More precisely, TCP needs three packets to establish a connection (the “three-way handshake”): a first one (called SYN, for synchronise) sent by the machine initiating the connection, a second one of consent and acknowledgement of receipt of the first (SYN-ACK) sent by the machine responding to the request, and a third, sent by the initiating machine, acknowledging receipt of consent (ACK). If the latency is 50 ms (milliseconds), it will take the initiating machine 100 ms to start to work seriously. Of course, if the purpose were to establish a connection in order to send an enormous file, these 100 ms would be absolutely insignificant relative to the total duration of the communication. But other Internet uses have different requirements. Such is the case with web surfing, where the surfer has to make numerous HTTP connections, and with the use of API (Application Programming Interface) based on HTTP, where the client may have to make numerous requests (which will bring us to RDAP, as I promised you in the title).
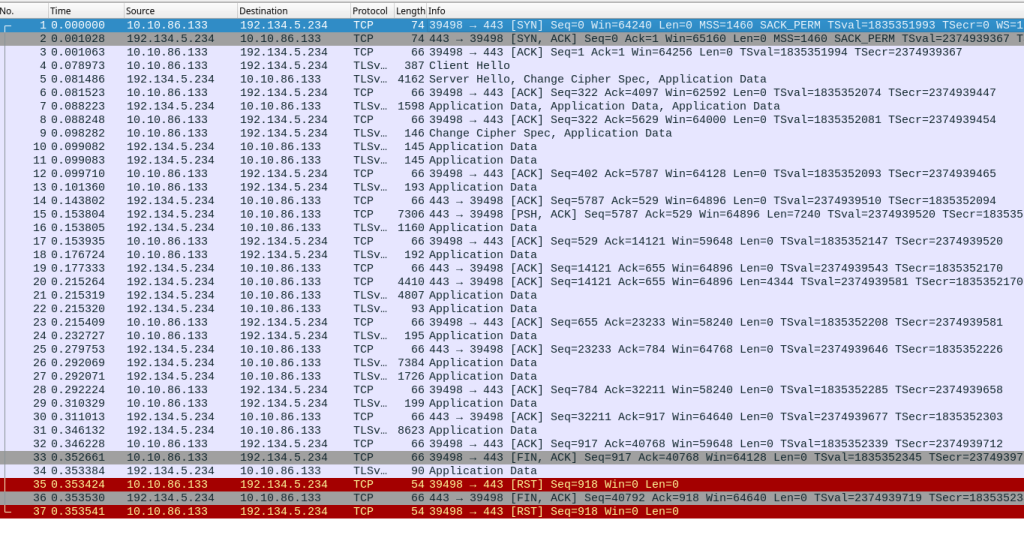
The situation is even worse if we use TLS (Transport Layer Security), an indispensable security protocol on the Internet. Once the TCP connection has been established, another return trip is needed to negotiate the TLS session. This is how the tshark4 tool presents this conversation:
1 0.000000000 2602:fbb1:1:245b::bad:dcaf → 2001:67c:2218:751::105 TCP 94 39214 → 443 [SYN] Seq=0 …
2 0.092198190 2001:67c:2218:751::105 → 2602:fbb1:1:245b::bad:dcaf TCP 94 443 → 39214 [SYN, ACK] Seq=0 Ack=1 …
3 0.092353978 2602:fbb1:1:245b::bad:dcaf → 2001:67c:2218:751::105 TCP 86 39214 → 443 [ACK] Seq=1 Ack=1 …
4 0.113281762 2602:fbb1:1:245b::bad:dcaf → 2001:67c:2218:751::105 TLSv1 479 Client Hello
5 0.206738104 2001:67c:2218:751::105 → 2602:fbb1:1:245b::bad:dcaf TLSv1.3 2942 Server Hello, Change Cipher Spec, Application Data
How do we read this? The first field is the number of the packet (packets numbered from 1 to 5), the second one is the time stamp, measured from the first packet, the third one is the IP address of the source and the fourth the IP address of the destination. Then comes the result of the decoding of the packet by tshark. Let’s take the first packet: machine 2602:fbb1:1:245b::bad:dcaf has contacted 2001:67c:2218:751::105 (.fr5 RDAP server) and requested a connection. The second packet, 92 ms later, is the positive response. Then we see the acknowledgement of receipt (packets 4 and 5) followed by the TLS negotiation, which tshark understands and can post.
In this example, the RDAP client was in the USA, the RDAP server in France, and the return trip transatlantic connection takes about 90 ms, as we can see with the “ping” command:
% ping -c 10 rdap.nic.fr
PING rdap.nic.fr(ingress-services.k8s02-th3.prive.nic.fr (2001:67c:2218:751::105)) 56 data bytes
…
--- rdap.nic.fr ping statistics ---
10 packets transmitted, 10 received, 0% packet loss, time 9011ms
rtt min/avg/max/mdev = 90.324/90.675/92.592/0.653 ms
here are various tools available that can reduce the time needed to establish a connection. TCP FO (FO = Fast Open) reduces the waiting time before you can send the request, and TLS session resumption simplifies the TLS negotiation, etc. However, these tools are not universally deployed, partly because they cause other problems. A more radical approach is to use a different transport protocol, such as QUIC, which combines transport and cryptography and allows faster connections, and can even survive a change of client’s IP address. But here too, QUIC is not widely deployed .
The HTTP solution
To accelerate the interaction of a HTTP client with the server, the HTTP protocol proposes another solution: persistent connections. Summary presentations of HTTP often say “the client opens a TCP connection, sends a HTTP request, receives a response, and closes the TCP connection”, but this is not the only way of doing things. In 1996, the HTTP 1.0 standard specified persistent connections. But these were already being used, and version 1.1 of the standard made it the default behaviour6. It is therefore possible to send several HTTP requests in a single session established with TCP and TLS7. So let’s talk about RDAP (Registration Data Access Protocol). This protocol for access to information stored in a registry of domain names or IP addresses aims to replace the ageing Whois8. One of the important choices made for RDAP was for it to be based on HTTP. So every RDAP request is a HTTP request, and this allows all the useful functions of HTTP, including persistent connections, to be recovered, which was one of the aims9. So any RDAP server can have persistent connections10.
Is it easy to use persistent connections? The good news is: yes it is. Most application libraries using HTTP manage these persistent connections11, and in general it is the default behaviour. So a typical RDAP client will benefit. And if you’re a programmer (RDAP was designed to allow easy development of clients), you have persistent connections without having to do anything12. Rather than disengaging this behaviour to create a new connection each time13, which will require a specific code.
Is it worth it? Let’s take a look at an RDAP client that allows persistent connections to either be used or not. The client is on the East Coast of the USA and the server is in France (90 ms round trip). We made three RDAP requests, for domains in the .re TLD14:
% time ./not-always-persistent courbu.re nic.re copacabana.re
...
./not-always-persistent courbu.re nic.re copacabana.re 0.09s user 0.05s system 20% cpu 0.706 total
% time ./not-always-persistent -no-reuse courbu.re nic.re copacabana.re
...
./not-always-persistent -no-reuse courbu.re nic.re copacabana.re 0.14s user 0.03s system 15% cpu 1.104 total
The command took 700 ms with the persistent connections and 1,100 without (option “no-reuse”). So we saved 30% on latency by re-using the connections. This gain would be less if the client and the server were closer together, and more if there were more than three requests15.
The source code
Let’s look now at the necessary code (the complete examples can be found at https://gitlab.rd.nic.fr/afnic/code-samples/-/tree/main/RDAP/persistent). In a language such as Go, you don’t have to do anything if you use the standard language library. You just do a simple http.get() and it all just happens: the HTTP connections are persistent and re-used. If you want to disengage the persistence, you have to create an http.transport with the right options (the complete code can be viewed on the above URL). In Elixir, with the supplementary library HTTPoison, you don’t have to do anything either. You just call up HTTPoison.get() as usual and the library manages the connections and re-uses them if possible. If you wish to deactivate the re-use of the connections, you have to remember that HTTPoison uses the Erlang Hackney library and that it is this that does the real work. So you have to send HTTPoison a [hackney: [pool: false]] argument (again, the complete code is available at the address indicated). In Python too, we use a supplementary library, Requests16. Requests manages persistent connections but, unlike the two other languages previously mentioned, requires its code to be slightly modified by explicitly creating sessions. Instead of directly calling requests.get(), we have to create the session (session = requests.Session()) and then use (session.get()).
Conclusion
So we see that in the struggle to continue gaining time, HTTP and therefore RDAP persistent connections are a useful optimisation tool, and one of the advantages of RDAP relative to Whois.
1 – And that’s assuming optimal routing, which is not always the case on the Internet.
2 – Half of it cannot be compressed, due to the limitation of the speed of light. Unlike capacity, which improves year by year, latency is unlikely to decrease much in the future.
3 – In the case of HTTP, it is not systematic—this protocol can also use QUIC, presented later.
4 – It is delivered with the excellent graphical application Wireshark. We could have used tcpdump, but it’s much harder to read.
5 – The address has obviously been found in the DNS, in exchange for the name rdap.nic.fr.
6 – The client sends a field saying “Connection: close” if he does not want persistent connections.
7 – Note that these persistent connections, while excellent for performance, may have drawbacks, for example in terms of privacy since they allow several requests to be made easily at the same time. For typical web browsing this is not a big problem, given the large number of other means of tracking (such as cookies).
8 – Among other shortcomings, Whois does not recognise persistent connections. Each request therefore needs a new TCP connection.
9 – There were others, such as the possibility of going through ultra-restricted networks that authorise only HTTP, which is often the case with public or business WiFi access points.
10 – For some unknown reason I was unable to make it work with .com’s RDAP server.
11 – This implies keeping the connections open in the memory and thus re-usable (the “HTTP keep-alive”), but also managing cases in which the server has cut off the connection from its side, which it always has the right to do, for example to economise on the use of its resources. So as you can see, it isn’t easy to do by hand.
12 – Unless you program the HTTP protocol yourself, which is not advisable, it is currently too complex to be a reasonable undertaking.
13 – And there would be no point in doing so, other than to measure the gain from persistent connections, as we shall see presently.
14 – The commands were typed three times, to make sure the measure is replicable and that the DNS memory contains the necessary data.
15 – As with any performance measure, the experiment can be improved ad infinitum. For example, the case in which the connections were not re-used would have been less worse in terms of latency if use had been made of the TLS session resumption, which was not the case.
16 – The standard language library allows HTTP requests to be made, but most Python programmers use Requests, which is easier and more comprehensive.
On the same topic
Featured
News

03/31/26
2025 review of the .fr:
a new all-time record for create ...
Afnic, the association responsible for .fr domain names, has ...
Expert papers
ICANN 2026 applications: what to expect after submitting your ...
Applications to create your own brandTLD may be submitted from ...
Agenda

05/12/2026