


La question
Lorsqu’on parle de performances, sur l’Internet, on se focalise souvent uniquement sur la capacité en bits par seconde. On suppose qu’avoir une capacité de 10 Gb/s (dix gigabits par seconde), c’est mieux qu’1 Gb/s. C’est vrai pour certaines applications, mais pas, pour toutes. Souvent, la variable importante est la latence, le temps que le message prend pour aller d’un point à un autre. S’il suffit d’une milli-seconde lorsque les deux machines sont dans la même région géographique1, il faut plusieurs milli-secondes à l’intérieur de l’Europe occidentale, plusieurs dizaines pour aller aux États-Unis2, et je ne parle même pas de l’Extrême-Orient ou de l’Afrique. Quelques milli-secondes de plus ou de moins, ce n’est pas important, me direz-vous ? Mais le problème est que certaines opérations nécessitent d’attendre une réponse et que plusieurs aller-retours peuvent être nécessaire. Il est donc important d’optimiser en limitant le nombre de ces aller-retours pendant lesquels les machines passent davantage de temps à attendre qu’à travailler.
Un bon exemple est celui de TCP (Transmission Control Protocol), le protocole de transport le plus utilisé sur l’Internet aujourd’hui. La plupart des protocoles applicatifs, comme le célèbre HTTP (Hypertext Transfer Protocol) utilisent TCP3. TCP repose sur le principe d’un établissement préalable de connexions entre machines. Avant toute chose, on échange des paquets IP (Internet Protocol) qui permettent d’être relativement sûrs que les deux machines consentent à communiquer. Et c’est seulement ensuite qu’on échange les vraies données. Plus précisément, TCP nécessite trois paquets pour établir une connexion : un premier (dit SYN pour synchronize) envoyé par la machine qui initie la connexion, un deuxième de consentement et d’accusé de réception du premier (SYN-ACK, ACK étant acknowledge) envoyé par la machine qui répond à la demande, et un troisième d’accusé de réception du consentement (ACK) envoyé par l’initiatrice. Si la latence était de 50 ms (milli-secondes), il faudra 100 ms à la machine initiatrice pour commencer à travailler sérieusement. Bien sûr, s’il s’agissait d’établir une connexion pour transférer un énorme fichier, ces 100 ms ne pèseraient rien par rapport à la durée totale de communication. Mais d’autres usages de l’Internet ont des exigences différentes. C’est le cas du Web, où le navigateur doit faire de nombreuses connexions HTTP, et de l’utilisation d’API (Application Programming Interface) reposant sur HTTP, où le client peut avoir à effectuer de nombreuses requêtes (ce qui va nous amener à RDAP, que je vous avais promis dans le titre).
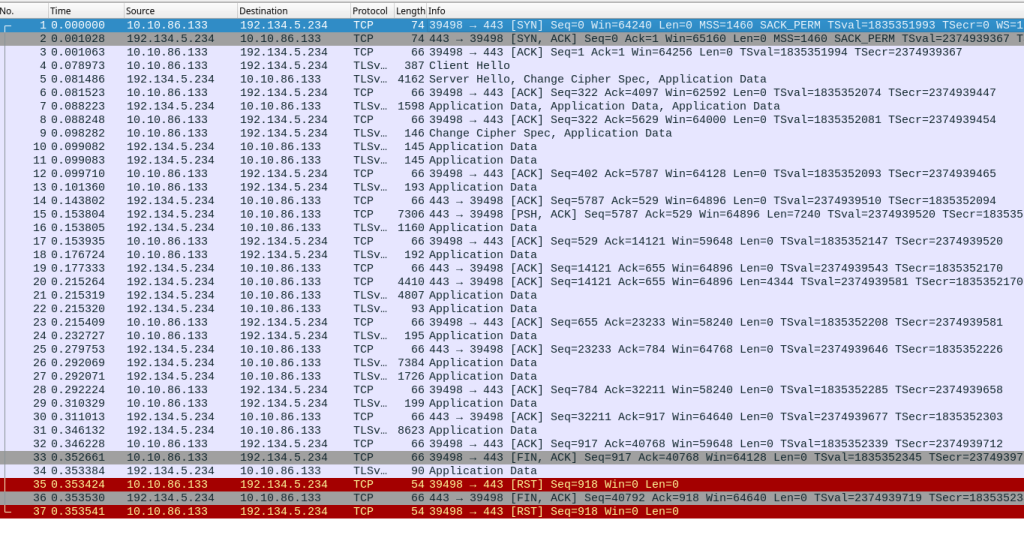
La situation est encore pire si on utilise TLS (Transport Layer Security), protocole de sécurité indispensable dans l’Internet. Une fois la connexion TCP établie, il faudra encore un aller-retour avec la négociation de session TLS. Voici comment l’outil tshark4 présente cette conversation :
1 0.000000000 2602:fbb1:1:245b::bad:dcaf → 2001:67c:2218:751::105 TCP 94 39214 → 443 [SYN] Seq=0 …
2 0.092198190 2001:67c:2218:751::105 → 2602:fbb1:1:245b::bad:dcaf TCP 94 443 → 39214 [SYN, ACK] Seq=0 Ack=1 …
3 0.092353978 2602:fbb1:1:245b::bad:dcaf → 2001:67c:2218:751::105 TCP 86 39214 → 443 [ACK] Seq=1 Ack=1 …
4 0.113281762 2602:fbb1:1:245b::bad:dcaf → 2001:67c:2218:751::105 TLSv1 479 Client Hello
5 0.206738104 2001:67c:2218:751::105 → 2602:fbb1:1:245b::bad:dcaf TLSv1.3 2942 Server Hello, Change Cipher Spec, Application Data
Comment est-ce que cela se lit ? Le premier champ est le rang du paquet (paquets numérotés de 1 à 5), le deuxième est l’estampille temporelle, mesurée depuis le premier paquet, le troisième est l’adresse IP de la source, le quatrième celle de la destination. Suit le résultat du décodage du paquet par tshark. Prenons le premier paquet : la machine 2602:fbb1:1:245b::bad:dcaf a contacté 2001:67c:2218:751::105 (serveur RDAP de .fr5) et a demandé une connexion. Le deuxième paquet, 92 ms plus tard, est la réponse positive. On voit ensuite l’accusé de réception puis (paquets 4 et 5), la négociation TLS, que tshark comprend et peut afficher.
Dans cet exemple, le client RDAP était aux USA, le serveur RDAP en France, et l’aller-retour par la liaison transatlantique prend environ 90 ms, comme on peut le voir avec la commande ping :
% ping -c 10 rdap.nic.fr
PING rdap.nic.fr(ingress-services.k8s02-th3.prive.nic.fr (2001:67c:2218:751::105)) 56 data bytes
…
--- rdap.nic.fr ping statistics ---
10 packets transmitted, 10 received, 0% packet loss, time 9011ms
rtt min/avg/max/mdev = 90.324/90.675/92.592/0.653 ms
Il existe des optimisations qui permettent de réduire le temps d’établissement de connexion. TCP FO (TCP Fast Open) permet d’attendre moins longtemps avant d’envoyer sa requête, la reprise de session (TLS session resumption) simplifie la négociation TLS, etc. Ces optimisations ne sont pas universellement déployées, en partie parce qu’elles soulèvent d’autres problèmes. Plus radicalement, on peut aussi utiliser un autre protocole de transport, comme QUIC, qui fusionne le transport et la cryptographie et permet des connexions plus rapides, et qui peuvent même survivre à un changement d’adresse IP du client. Mais, là aussi, QUIC n’est pas déployé partout .
La solution de HTTP
Pour accélérer l’interaction d’un client HTTP avec le serveur, le protocole HTTP propose une autre solution : les connexions persistantes. Les présentations sommaires de HTTP disent souvent « le client ouvre une connexion TCP, il envoie sa requête HTTP, il reçoit une réponse, il ferme la connexion TCP » mais cette façon de faire n’est pas la seule. En 1996, la norme HTTP 1.0 spécifiait les connexions persistantes. Mais elles étaient déjà utilisées, et la version 1.1 de la norme en faisait le comportement par défaut6.Il est donc possible d’envoyer plusieurs requêtes HTTP sur une seule session établie avec TCP et TLS7. Venons-en enfin à RDAP (Registration Data Access Protocol). Ce protocole d’accès à l’information stockée dans un registre de noms de domaine ou d’adresses IP vise à remplacer l’antédiluvien Whois8. Un des choix importants qui avaient été faits pour RDAP était de s’appuyer sur HTTP. Toute requête RDAP est donc une requête HTTP, ce qui permet, et c’était un des buts9, de récupérer toutes les fonctions utiles de HTTP, dont les connexions persistantes. Tout serveur RDAP peut donc avoir des connexions persistantes10.
Peut-on facilement utiliser ces connexions persistantes ? La bonne nouvelle est que oui. La plupart des bibliothèques logicielles mettant en œuvre HTTP gèrent ces connexions persistantes11, et c’est en général le comportement par défaut. Un client RDAP typique va donc en bénéficier. Et si vous êtes programmeuse ou programmeur (RDAP a été conçu pour permettre le développement facile de clients), vous avez les connexions persistantes sans faire d’effort12. C’est plutôt de débrayer ce comportement, pour créer une nouvelle connexion à chaque fois13, qui nécessitera du code spécifique.
Est-ce rentable ? Regardons avec un client RDAP qui permet d’utiliser ou pas les connexions persistantes. Le client est encore sur la côté Est des USA et le serveur en France (90 ms d’aller-retour). On fait trois requêtes RDAP, pour des domaines en .re14 :
% time ./not-always-persistent courbu.re nic.re copacabana.re
...
./not-always-persistent courbu.re nic.re copacabana.re 0.09s user 0.05s system 20% cpu 0.706 total
% time ./not-always-persistent -no-reuse courbu.re nic.re copacabana.re
...
./not-always-persistent -no-reuse courbu.re nic.re copacabana.re 0.14s user 0.03s system 15% cpu 1.104 total
La commande a pris 700 ms avec les connexions persistantes et 1 100 sans (l’option -no-reuse). On a donc gagné 30 % sur la latence en réutilisant les connexions. Ce gain serait moins élevé si le client et le serveur étaient plus proches, et plus élevé si on avait plus de trois requêtes15.
Le code source
Voyons maintenant le code nécessaire (les exemples complets sont en https://gitlab.rd.nic.fr/afnic/code-samples/-/tree/main/RDAP/persistent). Dans un langage comme Go, il n’y a rien à faire, lorsqu’on utilise la bibliothèque standard du langage. On fait donc un simple http.get() et tout va bien, les connexions HTTP sont persistantes et réutilisées. Si on veut débrayer la persistance, il faut créer un http.Transport avec les bonnes options (le code complet est visible, cf.L l’URL ci-dessus). En Elixir, avec la bibliothèque supplémentaire HTTPoison, il n’y a non plus rien à faire. On appelle juste HTTPoison.get() comme d’habitude et c’est la bibliothèque qui gère les connexions et les réutilise si possible. Si on veut supprimer la réutilisation des connexions, il faut se rappeler que HTTPoison utilise la bibliothèque Erlang hackney et que c’est elle qui fait réellement le travail. On doit donc passer à HTTPoison un argument [hackney: [pool: false]] (là encore, le code complet est disponible à l’adresse indiquée). En Python, on va aussi utiliser une bibliothèque supplémentaire, requests16. requests gère les connexions persistantes mais, contrairement aux deux langages précédents, il faut légèrement modifier son code en créant explicitement des sessions. Au lieu d’appeler directement requests.get(), on va créer la session (session = requests.Session()) puis l’utiliser (session.get()).
Conclusion
On voit donc que, dans la lutte pour continuer à gagner du temps, les connexions persistantes de HTTP, et donc de RDAP, sont une optimisation utile, et un des avantages de RDAP par rapport à Whois.
1 – Si le routage est optimal, ce qui n’est pas toujours le cas sur l’Internet.
2 – Dont la moitié est incompressible, en raison du caractère limité de la vitesse de la lumière. Contrairement à la capacité, qui s’améliore chaque année, la latence ne devrait guère diminuer dans le futur.
3 – Dans le cas de HTTP, ce n’est pas systématique, ce protocole peut aussi utiliser QUIC, présenté plus loin.
4 – Livré avec l’excellent logiciel graphique Wireshark. On aurait pu utiliser tcpdump, mais celui-ci est bien plus austère à lire.
5 – L’adresse a évidemment été trouvée dans le DNS, en échange du nom rdap.nic.fr.
6- Le client envoie un champ « Connection : close » s’il ne veut pas de connexions persistantes.
7 – Notez que ces connexions persistantes, excellentes pour les performances, peuvent avoir des défauts, par exemple pour la vie privée puisqu’elles permettent trivialement de relier plusieurs requêtes. Dans le cadre de l’utilisation typique du Web, ce n’est guère un problème, vu le grand nombre d’autres moyens d’assurer ce suivi (les cookies, par exemple).
8 – Entre autres défauts, Whois n’a pas la notion de connexions persistantes. Chaque requête va donc nécessiter une toute nouvelle connexion TCP.
9 – Il y en avait d’autres, comme la possibilité de passer à travers des réseaux ultra-restreints, qui n’autorisent que HTTP, ce qui est fréquent dans les points d’accès Wifi publics, ou bien en entreprise.
10 – Pour une raison inconnue, je ne suis pas arrivé à le faire marcher avec le serveur RDAP de .com.
11 – Cela implique de garder en mémoire les connexions ouvertes et donc réutilisables, mais aussi de gérer le cas où le serveur a coupé la connexion de son côté, ce qu’il a toujours le droit de faire, par exemple pour économiser ses ressources. On voit donc que ce n’est pas trivial à faire à la main.
12 – Sauf si vous programmez le protocole HTTP vous-même, ce qui est déconseillé, il est aujourd’hui trop complexe pour que cela soit une entreprise raisonnable.
13 – Et cela n’aurait aucun intérêt, à part de mesurer ce que les connexions persistantes font gagner, comme on le voit plus loin.
14 – Les commandes ont été tapées trois fois, pour être sûr que la mesure est reproductible, et pour que la mémoire du résolveur DNS contienne les données nécessaires.
15 – Comme avec toute mesure de performance, on peut améliorer l’expérience à l’infini. Par exemple, le cas où on ne réutilise pas les connexions serait moins mauvais en latence si on avait utilisé la reprise de session TLS, ce qui n’a pas été le cas.
16 – La bibliothèque standard du langage permet de faire des requêtes HTTP, mais la plupart des programmeurs et programmeuses Python utilise requests, plus facile et plus complète.
Sur le même sujet
À la une
Actualités

06/07/26
Observatoire des noms de domaine : +6,2 % de croissance du marché ...
L’édition 2025 de l’analyse annuelle « Le marché ...
Papiers d'experts

Comment le DNS peut-il aider à identifier les drones à distance ...
Dans le cadre du programme Cassiopée de Télécom SudParis, ...
